SAP has a webpage with a tutorial on using their Predictive Analytics 2.3 tool(formerly KXEN Modeler)using daily data. They released this back in December, but didn't see until browsing Twitter. It provides an unusual public record of what comes out of SAP. They didn't publish the model with p-values and all of the output, but this is good enough to compare against. We ran numerous scenarios with different modeling options to understand what the outcome would be using these modeling(ie variable) techniques. Autobox has some default variables it brings in with daily data. We will have to suppress some of those features so that when we use the SAP variables they don't collide with them and make a multicollinear regression.
The Tutorial is well written and allows you to easily download the 1,724 days of data and model this yourself. While SAP had a .13 MAPE(in sample), they had a challenge at the end for those who get a MAPE less than .12 to contact them. Can you predict what Autobox did? .0724. Guess who is going to contact them? I will also add, that if you can do better contact us as we might have something to learn too. I also suggest that you post how other tools handle this as well as that would be interesting to see as well. Autobox thrives(1st among automated) on daily data as it did in a daily forecasting competition and is much more difficult to model and something we have dedicated 25 years to perfecting.
After reading the SAP user's guide let's make the distinction that Autobox uses all of the data to build the model, while SAP (like all other tools) withholds data to "train" on.
Autobox adjusts for outliers. One could argue that by using adjusting for outliers the MAPE will only go down which is true, but it be aware that it allow for a clearer identification of the relationships in the data( ie coefficients / separating signal from noise).
The first approach in the SAP tutorial is running with only historical data and they add in the causals later. Outliers are identified and has a MAPE of .197.
66 Variables
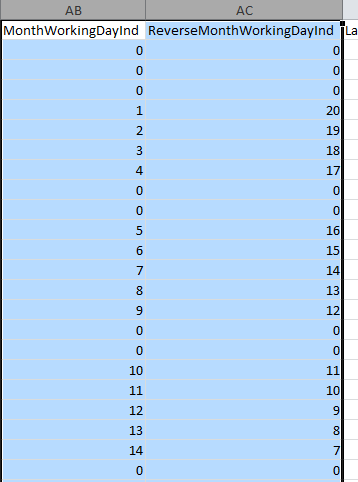
A bunch of very curious variables(66??----PenultimateWednesday) are included that we have never seen before which made us scratch our heads (with delight???). They seem to try and capture the day of the week so we will turn that off some of Autobox's searches to avoid collinearity when we run with these in the first pass. They seem to use a day of year variable which I have never seen before. What book are they getting ideas to use these kind of variables from? Not one that I have ever seen, but perhaps someone can enlighten me? There are two variables that are measuring the number of working days that have occurred in the month and the number left in the month. We did find that some of these variables do have importance in the tests we ran so SAP has some ideas generating useful variables, but many are collinear and this could be called "kitchen sink" modeling. We will do more research into these. There is a holiday variable which also flags working days so the two variables would seem to be collinear. These two end up as the second and third most powerful variables in the SAP model. When we tried these in Autobox, both runs found them significant. Perhaps they measure (implicitly) holidays too? We are not sure, but they help.
There are weather variables which are useful and actually represent seasonality so using both monthly dummies/weekly dummies and the weather variables could be problematic. The holidays have been all combined into one catch all variable. This assumes that each holiday behaves similarly. It should be noted that a major difference is that SAP does not search for lead or lag relationships around the causals while Autobox can do that. Just try running this example in Autobox and then SAP. We ran with all of these curious variables. We then reduced these variables and kept only Holiday, gust, rain, tmean, hmean, dmean, pmean, wmean, fmean, TubeStrike and Olympics and removed the curious other variables. The question which might arise "how much can you trust the weather predictions?", but here we are looking at only the MAPE of the fit so that is not a topic of concern.
SAP ended up with a .13 MAPE when using there long list of causals. The key here is that no outliers are identified in the analysis. This is a distinction and why Autobox is so different. If you ignore outliers they do still exist and yes they exist in causal problems. By ignoring something that doesn't mean it goes away, but ends up impacting you elsewhere such as the model and you likely aren't even aware of its impact. By not being able to deal with outliers your model with causals will be skewed, but no one talks about this in any school or text book so sorry to ruin this illusion for you. Alice in Wonderland(search on alice) thought everything was perfect too, until.....
Autobox does stepdown regression, but also does "stepup" where it will search for changes in seasonality(ie day of the week), trend/level/parameters/variance as things sometimes drastically change. If you're not looking for it then you will never find it! s. The MAPE we are presenting can be found in the detail.htm audit report from the Autobox run(hint:near the bottom). We suppressed the search for special days of the month which are useful in ATM data, but not theoretically plausible for this data. Autobox allows for holidays in the Top 15 GDP's, but in general assumes the data is from the US so we will need to suppress that search. We suppressed the search for special days of the month which are useful in ATM daily data as payday's are important, but not theoretically plausible for this data.
To summarize: We can run this a few different ways, but we can't present all of these results down below as it would be too much information to present here. We included some output and the Autobox file (current.asc-rename that if you want to reproduce the results) so you can see for yourself. What we do know is that including ARIMA increases run time.
MAPE's
- Run using all variables with Autobox default options(suppressing US Holidays, day of month and monthly/weekly dummies). .0883
- Run using all variables with Autobox default options(suppressing US Holidays, day of month and monthly/weekly dummies). Allow for ARIMA .0746
- Run using a reduced set of variables(see above) & suppressing US holidays, day of month and monthly/weekly dummies). .1163
- Run using a reduced set of variables(see above) & suppressing US holidays, day of month and monthly/weekly dummies). Allow for ARIMA .0732
- Run using only Holiday, Strike/Olympics and rely upon monthly or weekly dummies. .1352
- Run using only Holiday, Strike/Olympics and rely upon monthly or weekly dummies. Allow for ARIMA .1145
- Run using a reduced set of variables, but remove the catch all "holiday" variable and create separate 6 main holiday variables that were flagged by SAP as they might each behave differently. (suppressing US Holidays, day of month, and monthly/weekly dummies) .1132
- Run using a reduced set of variables, but remove the catch all "holiday" variable and create separate 6 main holiday variables that were flagged by SAP as they might each behave differently. (suppressing US Holidays, day of month, and monthly/weekly dummies). Allow ARIMA .0724
Let's consider the model that was used to develop the lowest MAPE of .0724.
There were 38 outliers identified over the 1,724 observations so the goal is not to have the best fit, but to model and be parsimonious.
So, what did we do to make things right? We started by deleting all kinds of variables. There were linearly redundant variables such as WorkingDay that is perfectly correlated (inverse here) to Holiday which by definition should never be done when using dummy variables. The variable "Special Event" is redundant with TubeStrike and Olympics as well. Special Event name isn't even a number, but rather text and also is redundant.
All other software withholds data whereas Autobox uses all of the data to build the model as we have adaptive technology that can detect change (seasonality/level/trend/parameters/variance plus outliers). We won best dedicated forecasting tool in J. Scott Armstrong's "Principles of Forecasting". For the record, we politely disagree against a few of the 139 "Principles" as well.
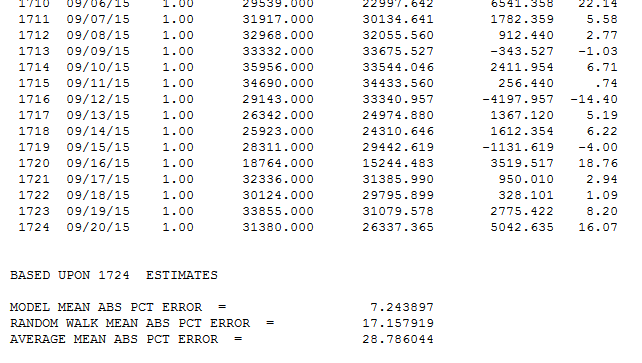
We report the in sample MAPE, in the file "details.htm" seen below...
Another way to compare the Autobox and SAP results are by comparing side by side the actual and fit and you will clearly see how Autobox does a better job. The tutorial shows the graph for univariate, but unfortunately not for the causal run! Here is the graph of the actual, fit and forecast.
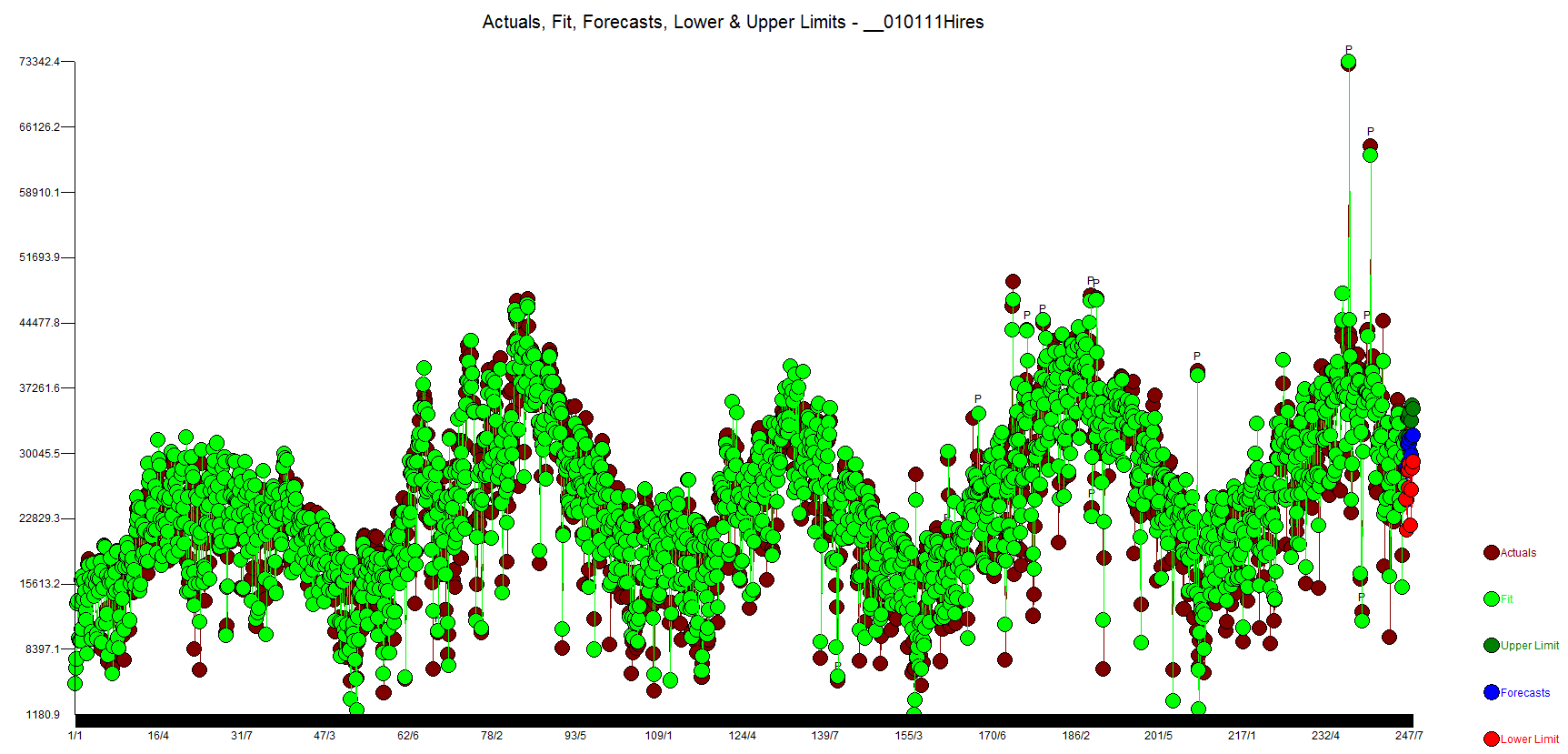
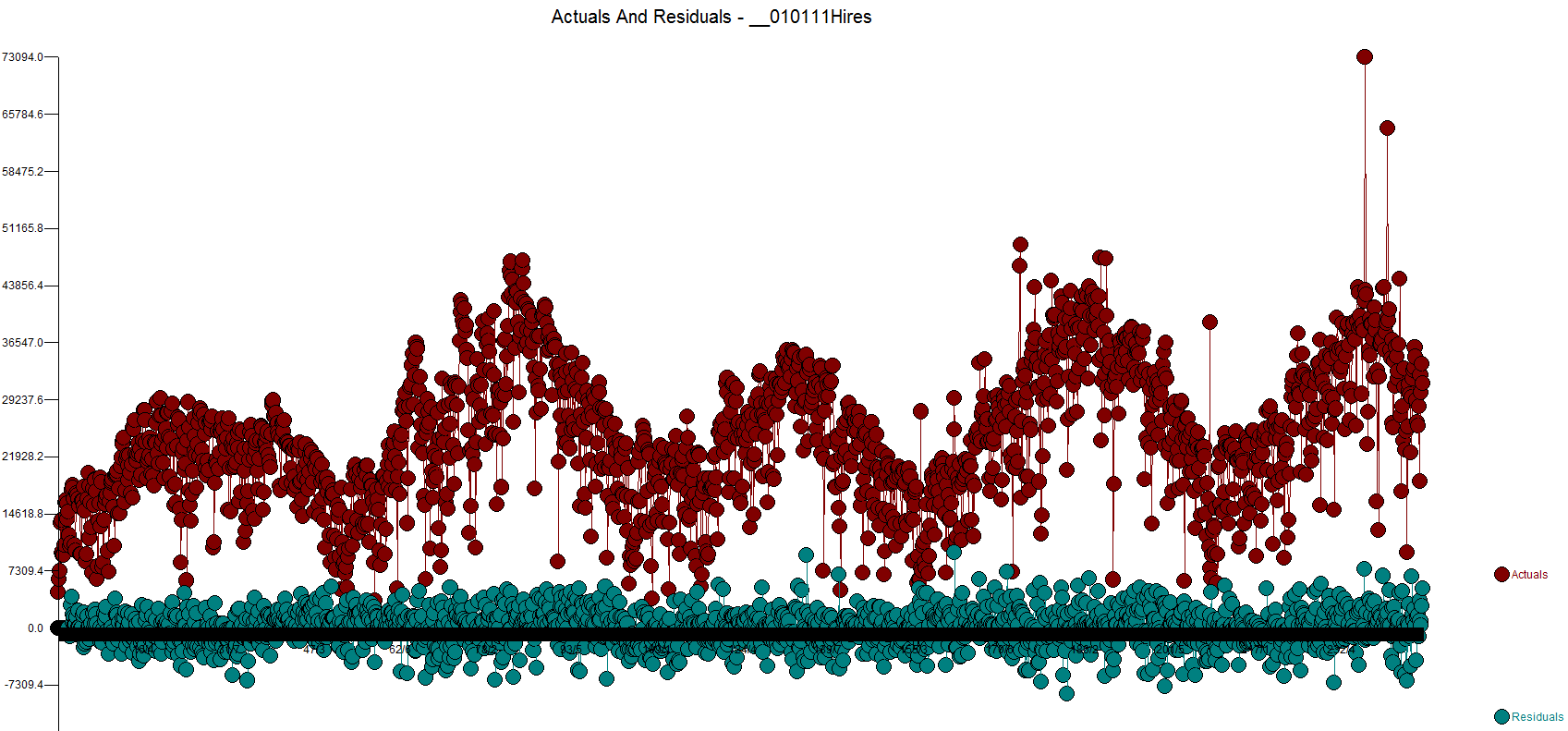
We prefer the actual and residuals plot as you can see the data more clearly.
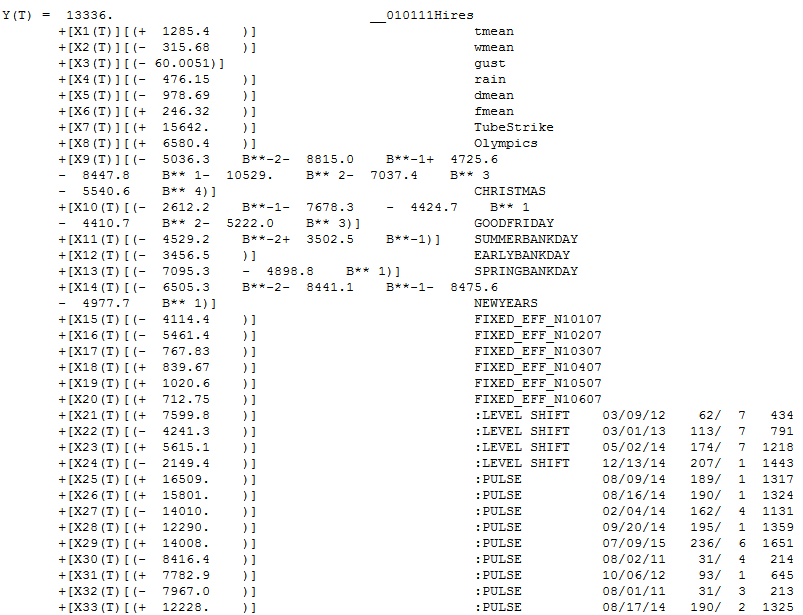
Let's review the model
The sign of the coefficients make sense(for the UK which is cold). When it's warmer people will skip the car and use the bike, for example so when Temperature goes up (+ sign) then people rent more bikes. When its gusty people will not and just drive. The tutorial explains the variables names in the back. tmean is average temperature, w is wind, d is dewpoint, h is humidity, p is barometric pressure, d is real feel temperature. All 6 holidays were found to be important with all but one having lead or lag impacts. When you see a B**-2 that means two days before the Christmas volume was low by 5036. Autobox found all 6 days of the week to be important. The SAP Holiday variable was a mixture of Saturday and Sunday and causes some confusion with interpretation of the model. This approach is much cleaner. The first day of the data is a Saturday(1/1/2011) and the variable "FIXED_EFF_N10107" is measuring that impact that Saturday is low by 4114. Sunday is considered average as day 7 is the baseline. See below for more on the day of the week rough verification(ie pivot table/contribution %).
Note the "level shift' variables added to the model. This meant that the volume changed up or down for a period and Autobox identified and ADAPTED to it. We call this "step up regression"(nothing there right? Yes, we own that world!) as we are identifying on the fly deterministic variables and adding them to the model. The runs with the SAP variables fit 2012 much better. The first time trend began at period 1 with volume steadily increasing 10.5 units each day. This gets tampered down with the second time trend beginning at 177 making the net effect +4.3 increase per day. 38 outliers were identified which is the key to whole analysis. They are sorted by their entry into the model and really their importance.
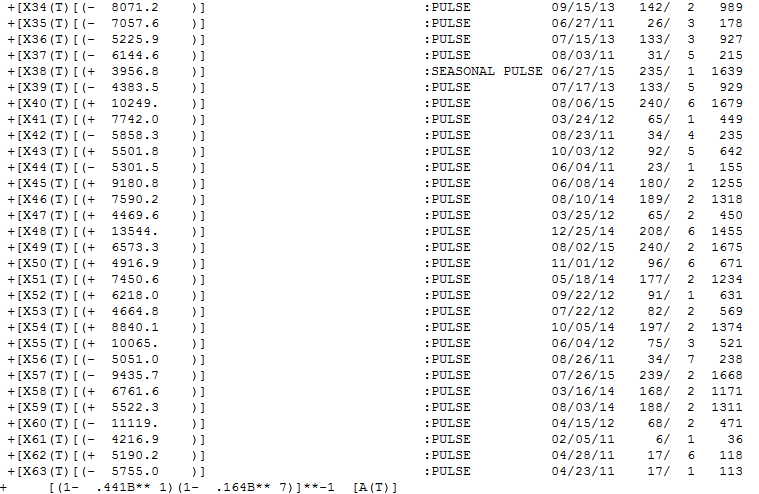
Note the Seasonal pulse where the first day becomes much higher starting at period 1639 and forward with an average 3956.8 higher volume. Thats quite a lot and if you do some simple plotting of the data it will be very apparent. Day 1 and Day 2 were always low, but over time Day 1 has become more average, Note the AR1 and AR7 parameters.
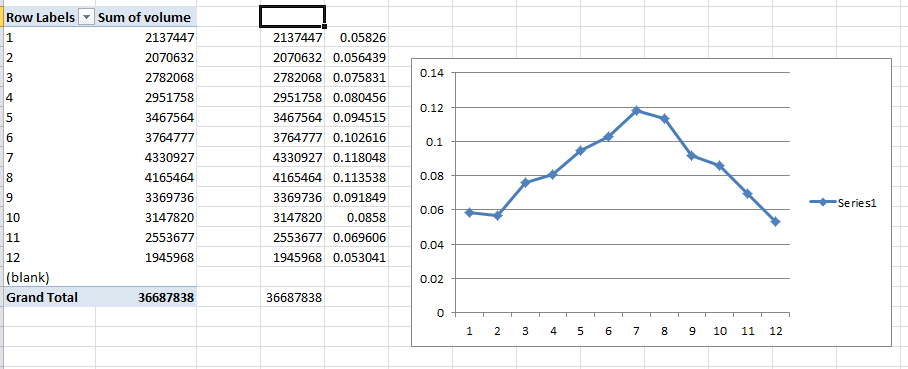
Let's consider the day of the week data by building a pivot table.
And getting this % of the whole. We call this the contribution %. Day 7 in Excel is Saturday which is low and notice Sunday(baseline) is even lower(remember that the holiday variable had a negative sign? The sign for Saturday was +1351.5 meaning it was 1351 higher than Sunday which matches the plot below. This type of summarization ignores trend, changes in day of the week impacts, etc. so be careful. We call this a poor man's regression because those percentages would be the coefficient if you ran a regression just using day of the week. It is directional, but by not means accurate as Autobox. We use this type of analysis to "roughly verify" Autobox with day of the week dummies, monthly dummies, and day of the month effects using pivot tables. The goal is not to overfit, but rather be parsimonious. Auto.arima is not parsimonious.
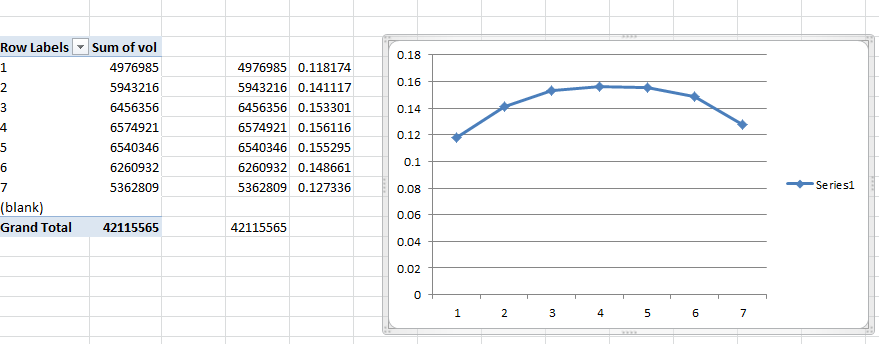
Let's look at the monthly breakout. Jan,Feb,Dec are average and the other months are higher with a slope up to the Summer months and down back to Winter. The temperature data replaces the use of monthly or weekly dummies here.